I don’t think it is hyperbole to say that HTML5 will change the way that you think about web development. I welcome many of the changes as they make development easier, and the user experience richer. With any change, though, there is certain to be a bit of trepidation and controversy. One addition that certainly is not without its controversy is the Microdata specification, but I believe the benefits of this very simple specification are going to change how you look at your mark-up in the very near future.
Introduction and Scope: Context for Machines
I am focusing on the Microdata specification in this tutorial. You do need to understand that the specification is not solid at the moment, nor is it widely adopted. In fact, during the course of my writing, the specification changed. That said, Microdata has been adopted by Google as another way of providing rich search results back to the user. In addition to being an immature specification, there is a bit of controversy surrounding Microdata.
To understand the controversy, you need to understand that Microdata is a subset of making a document have meaning to machines, just as it has meaning to a reader of the document. With meaning, I mean providing the meta data in such a way that can be used by a machine reading the document and to allow that data to be processed. It’s controversial as there are other formats and specifications that also have this same end goal in mind. RDFa and Microformats are two of these other formats which you might be familiar with, and may well be using today.
In a perfect world, there wouldn’t be competing specifications that we would have to aware of, but unfortunately, there are far greater issues to worry about. In addition, each format has its downside, in terms of use. All of this aside, let’s instead stick to the positive and learn what the specification brings to us, as well as what we can utilize today to add a bit more meaning to our documents.
One note before we get started: regardless of the format that you prefer, you should never have one set of mark-up for what your users see, and another set for what machines see. There may be times when you do need to provide specific meta data to a machine, but the use should be the exception, and not the rule. The purpose of these formats is to provide context, not to trick a search engine or other application into reading more into a page than what is actually there. You will regret using tricks using the hidden attribute or display: none, as it would definitely be frowned upon.
“Microdata is a subset of making a document have meaning to machines, just as it has meaning to a reader of the document. With meaning, I mean providing the meta data in a way that can be used by a machine reading the document and to allow that data to be processed”
Microdata in Theory: The Big Picture
Suppose you are a collector of comic books. I would bet a person that collects comics not only reads up on the upcoming issues, but also explores the web to complete their collection of comics as well as their knowledge of the stories they are interested in. That exploration might be as simple as spending time at Google, typing in query after query about your interest. Some pages will be hit or miss, as they might mention Superman, but not necessarily in the context that you are after. It would be nice if Google had context from the pages that they had indexed to serve you the correct search results. That provides a richer experience for the user, and it connects you with the people that value your website. It’s a win / win.
Let’s take that a step further past search results. Say you write an application that joins like-minded and willing websites to combine their knowledge about comic books. We could obviously write a scraper, but we don’t really have the context, as probably none of the websites are using the same format to display their results. We might have to write several scraper formats just to get the basic information. Instead, we can define a new format specification and with the help of Microdata and the five attributes that will ease this problem.
Microdata in Theory: New Global Attributes
Microdata introduces five simple global attributes (available for any element to use) which give context for machines about your data. These five new attributes are: itemid, itemprop, itemref, itemscope, and itemtype. Microdata is basically a group of item value pairs and the attributes give meaning to our items. Let’s look at them in detail.
The itemscope attribute is a boolean attribute that tells any machine that is reading our document that there is Microdata on this page, and this is where it starts. You are creating the item with the use of itemscope. Any element with an itemscope can also have the itemtype attribute. The itemtype is a valid URL which defines the item and provides the context for the properties. Also, you could have an itemid, which is the vocabulary that the item type uses, so that we are making descriptions in the proper format of the definition.
Using the example from the specification:
<dl itemscope
itemtype="http://vocab.example.net/book"
itemid="urn:isbn:0-330-34032-8">
We have an item identified by our itemscope. The item definition can be found at http://vocab.example.net/book, and the exact meaning of the item can be found using the vocabulary of the itemid. In this case, we are identifying a book with the isbn of 0-330-34032-8.
The final two attributes for the Microdata is itemprop and itemref. Itemprop defines a property of the item. Remember, Microdata is basically item value pairs, meaning here is the value for this property. So, the itemprop is giving the context of our item. Finally, we have itemref, which allows us to keep the flow of our documents for our users. Remember, we are giving context to our HTML document, not trying to build a new document for an application or search engine. Let’s look at our example again, this time deviated a bit from the provided example from the specification:
<dl itemscope
itemtype="http://vocab.example.net/book"
itemid="urn:isbn:0-330-34032-8"
itemref="author_information">
<dt>Title
<dd itemprop="title">The Reality Dysfunction
<dt>Author
<dt>Publication date
<dd><time itemprop="pubdate" datetime="1996-01-26">26 January 1996</time>
</dl>
<div id="author_information" itemprop="author">Peter F. Hamilton</div>
In our example, we have properties with values now. We also keep with the flow of the document, by referencing an ID of author information. A machine would then be able to understand this by parsing our item, and getting this context, and if we think in an array format:
Item Type: http://vocab.example.net/book ID: urn:isbn:0-330-34032-8 title = The Reality Dysfunction pubdata = 1996-01-26 author = Peter F. Hamilton
Now, our array of data can be translated by a machine, or changed to other formats such as JSON, N-Triples, or any other internal format that an application might need.
This is the reason I like Microdata, because it’s easy to understand and easy to execute. Let’s look at some examples that we can use today, particularly in how we can provide some context to Google, and how they might use that context. I will keep the format as close to the Google examples as I can, but change the products, people, to different real world examples.
Microdata in Practice: People and Businesses
If you have ever searched someone’s LinkedIn results, you might have seen something like this:

Google will process three formats currently. They are RDFa, Microformats, and you guessed it, Microdata. We can now provide context from our HTML to give better search results. While LinkedIn uses Microformats, let’s see if we can get a similar result using Microdata:
<div itemscope itemtype="http://data-vocabulary.org/Person">
<img src="avatar.jpg" itemprop="photo">
My name is <span itemprop="name">John Cox</span>, and I am a <span itemprop="title">writer</span> for
<a href="http://net.tutsplus.com" itemprop="affliation">Nettuts+</a>.
I live in
<span itemprop="address" itemscope
itemtype="http://data-vocabulary.org/Address">
<span itemprop="locality">Louisville</span>,
<span itemprop="region">KY</span>
</span>
</div>
While this little snippet produces something that looks like this unformatted:

When I test what the Google results would show about me, I get this:
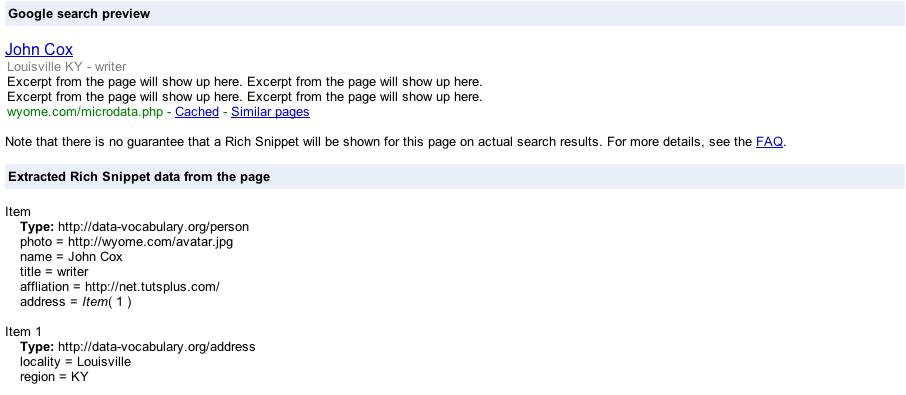
While the snippet is interesting, notice also the extra context that Google has about me:

The more context I provide, the more context that Google or any other application that reads my page will have about me.
Let’s take this one step further, and look at a business or organization, and see if we can’t give a little more context for a machine. In this example, I will use Nettuts+.
<address itemscope itemtype="http://data-vocabulary.org/Organization">
<span itemprop="name">Nettuts+</span>
Postal Address:
<span itemprop="address" itemscope
itemtype="http://data-vocabulary.org/Address">
<span itemprop="street-address">PO Box 21177</span>,
<span itemprop="locality">Melbourne</span>,
<span itemprop="region">Victoria</span>,
<span itemprop="country-name">Australia</span>.
</span>
<span itemprop="geo" itemscope itemtype="http://www.data-vocabulary.org/Geo/">
Latitude: <span itemprop="latitude">37.49 S </span>
Longitude: <span itemprop="longitude">144.58 E</span>
</span>
Phone: <span itemprop="tel">+61 (0) 3 9023 0074</span>
<a href="http://net.tutsplus.com/" itemprop="url">Nettuts+ | Web development tutorials, from beginner to advanced.</a>.
</address>
Unfortunately, Google does not have a rich snippet for organizations yet, but let’s look at the data that they do see.

Again, we are providing context back to a machine, which can be used in various ways, such as plotting our organization on a map with relative ease.
Microdata in Practice: Products and Reviews
Another practical use for Microdata is giving more context about the products that we sell, whether that is about the product, or perhaps how people rate the product. Let’s take a look at product information first.
<div itemscope itemtype="http://data-vocabulary.org/Product"> Brand: <span itemprop="brand">Bridgestone</span> Category: <span itemprop="category">Truck Tires</span> <h1><span itemprop="name">R-195F</span> </h1> <span itemprop="photo"><img src="http://www.bfentirenet.com/tires/b_r195f.jpg"/></span> On sale for <span itemprop="price">$300.09</span>. Find more information from <a href="http://www.bridgestonetrucktires.com" itemprop="url">Bridgestone</a> . </div>
Once again, Google does not have a rich snippet for a product, but we can see the context that they see when they parse our page:

They do have a rich snippet for reviews though, and that is what we are building towards. Let’s say that we allow ratings about our products:
<div itemscope itemtype="http://data-vocabulary.org/Review">
<span itemprop="itemreviewed">R-195F</span>
By <span itemprop="reviewer">John Cox</span> on
<time itemprop="dtreviewed" datetime="2010-06-10">June 10, 2010</time>.
<span itemprop="summary">This tire runs forever!</span>
Rating: <span itemprop="rating">4.5</span>
</div>
With just this little additional mark-up we can give context to our review for machines to consider. Google would display the review as:
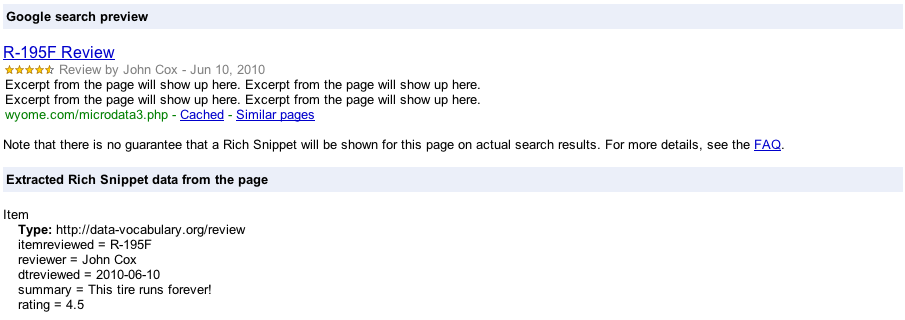
It’s all a matter of giving context through five simple global attributes. We can now provide a consistent method of giving that context, whether we are reviewing tires, or websites, or games.
Microdata in Practice: Events
The final example to talk about is the ability of giving some context of upcoming events through Microdata. Events are a common searched item. You may well be working on a website that has scheduled events, which you want to show. Let’s give a little more context for machines and see how it might be used:
<div itemscope itemtype="http://data-vocabulary.org/Event">
<a href="http://www.thedevilmakesthree.com" itemprop="url" >
<span itemprop="summary">The Devil Makes Three</span>
</a>
<img itemprop="photo" src="http://www.thedevilmakesthree.com/MediaFiles/right_column/do-wrong-right.jpg" />
<span itemprop="description">We are off again down the eastern side of these United States on our way to The Bonnaroo music festival. We The Devil Makes Three will be performing <span itemprop="eventType">concerts</span> for your enjoyment in eight states over the next two weeks. </span>
<time itemprop="startDate" datetime="2010-06-13">June 13th, 2010</time>
<span itemprop="location" itemscope itemtype="http://data-vocabulary.org/Organization">
<span itemprop="name">Bonnaroo</span>
</span>
</div>
Which will produce a nice entry like this:
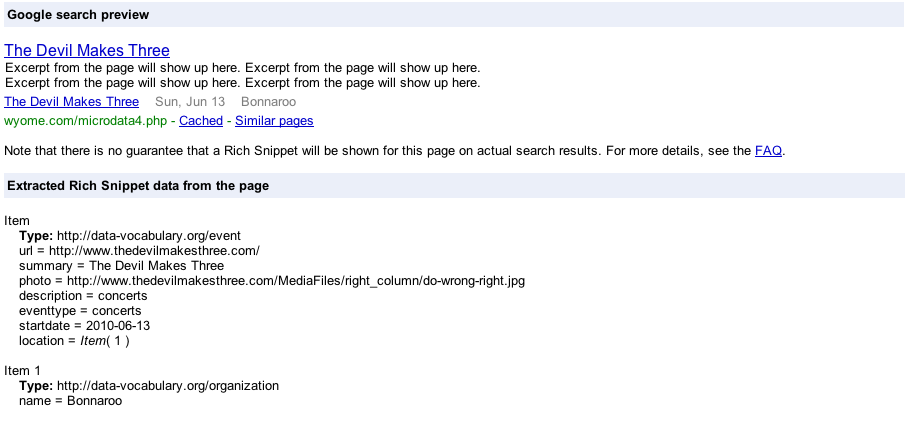
Now we have our event listed on our search result, in addition to our own website. Again, we are giving context to our data in a way that can be easily recognized by other applications.
Conclusion
It’s important to stress again that the Microdata specification is young, and is going through changes. It’s equally important to understand that while I focused on Google search results, there are plenty of other applications. For my purposes, Google presented me with the best way of showing Microdata in action, which was a bit of a challenge for me. The other alternate formats are much more mature, and have been in use for quite some time. Also, one other important consideration, is that Google is currently hand reviewing every rich text snippet entry:

Microdata is very easy to use, and implement. While the specification isn’t particularly clear for the layman on the definitions of the attributes, I do hope I helped shed some light. It doesn’t take much to be an expert with Microdata, at least until the specification changes (again). Please share your thoughts and experiences with this young HTML5 format in the comments.