Who’s to blame for the leaking of 50 million Facebook users’ data? Facebook founder and CEO Mark Zuckerberg broke several days of silence in the face of a raging privacy storm to go on CNN this week to say he was sorry. He also admitted the company had made mistakes; said it had breached the trust of users; and said he regretted not telling Facebookers at the time their information had been misappropriated.
Meanwhile, shares in the company have been taking a battering. And Facebook is now facing multiple shareholder and user lawsuits.
Pressed on why he didn’t inform users, in 2015, when Facebook says it found out about this policy breach, Zuckerberg avoided a direct answer — instead fixing on what the company did (asked Cambridge Analytica and the developer whose app was used to suck out data to delete the data) — rather than explaining the thinking behind the thing it did not do (tell affected Facebook users their personal information had been misappropriated).
Essentially Facebook’s line is that it believed the data had been deleted — and presumably, therefore, it calculated (wrongly) that it didn’t need to inform users because it had made the leak problem go away via its own backchannels.
Except of course it hadn’t. Because people who want to do nefarious things with data rarely play exactly by your rules just because you ask them to.
There’s an interesting parallel here with Uber’s response to a 2016 data breach of its systems. In that case, instead of informing the ~57M affected users and drivers that their personal data had been compromised, Uber’s senior management also decided to try and make the problem go away — by asking (and in their case paying) hackers to delete the data.
Aka the trigger response for both tech companies to massive data protection fuck-ups was: Cover up; don’t disclose.
Facebook denies the Cambridge Analytica instance is a data breach — because, well, its systems were so laxly designed as to actively encourage vast amounts of data to be sucked out, via API, without the check and balance of those third parties having to gain individual level consent.
So in that sense Facebook is entirely right; technically what Cambridge Analytica did wasn’t a breach at all. It was a feature, not a bug.
Clearly that’s also the opposite of reassuring.
Yet Facebook and Uber are companies whose businesses rely entirely on users trusting them to safeguard personal data. The disconnect here is gapingly obvious.
What’s also crystal clear is that rules and systems designed to protect and control personal data, combined with active enforcement of those rules and robust security to safeguard systems, are absolutely essential to prevent people’s information being misused at scale in today’s hyperconnected era.
But before you say hindsight is 20/20 vision, the history of this epic Facebook privacy fail is even longer than the under-disclosed events of 2015 suggest — i.e. when Facebook claims it found out about the breach as a result of investigations by journalists.
What the company very clearly turned a blind eye to is the risk posed by its own system of loose app permissions that in turn enabled developers to suck out vast amounts of data without having to worry about pesky user consent. And, ultimately, for Cambridge Analytica to get its hands on the profiles of ~50M US Facebookers for dark ad political targeting purposes.
European privacy campaigner and lawyer Max Schrems — a long time critic of Facebook — was actually raising concerns about the Facebook’s lax attitude to data protection and app permissions as long ago as 2011.
Indeed, in August 2011 Schrems filed a complaint with the Irish Data Protection Commission exactly flagging the app permissions data sinkhole (Ireland being the focal point for the complaint because that’s where Facebook’s European HQ is based).
“[T]his means that not the data subject but “friends” of the data subject are consenting to the use of personal data,” wrote Schrems in the 2011 complaint, fleshing out consent concerns with Facebook’s friends’ data API. “Since an average facebook user has 130 friends, it is very likely that only one of the user’s friends is installing some kind of spam or phishing application and is consenting to the use of all data of the data subject. There are many applications that do not need to access the users’ friends personal data (e.g. games, quizzes, apps that only post things on the user’s page) but Facebook Ireland does not offer a more limited level of access than “all the basic information of all friends”.
“The data subject is not given an unambiguous consent to the processing of personal data by applications (no opt-in). Even if a data subject is aware of this entire process, the data subject cannot foresee which application of which developer will be using which personal data in the future. Any form of consent can therefore never be specific,” he added.
As a result of Schrems’ complaint, the Irish DPC audited and re-audited Facebook’s systems in 2011 and 2012. The result of those data audits included a recommendation that Facebook tighten app permissions on its platform, according to a spokesman for the Irish DPC, who we spoke to this week.
The spokesman said the DPC’s recommendation formed the basis of the major platform change Facebook announced in 2014 — aka shutting down the Friends data API — albeit too late to prevent Cambridge Analytica from being able to harvest millions of profiles’ worth of personal data via a survey app because Facebook only made the change gradually, finally closing the door in May 2015.
“Following the re-audit… one of the recommendations we made was in the area of the ability to use friends data through social media,” the DPC spokesman told us. “And that recommendation that we made in 2012, that was implemented by Facebook in 2014 as part of a wider platform change that they made. It’s that change that they made that means that the Cambridge Analytica thing cannot happen today.
“They made the platform change in 2014, their change was for anybody new coming onto the platform from 1st May 2014 they couldn’t do this. They gave a 12 month period for existing users to migrate across to their new platform… and it was in that period that… Cambridge Analytica’s use of the information for their data emerged.
“But from 2015 — for absolutely everybody — this issue with CA cannot happen now. And that was following our recommendation that we made in 2012.”
Given his 2011 complaint about Facebook’s expansive and abusive historical app permissions, Schrems has this week raised an eyebrow and expressed surprise at Zuckerberg’s claim to be “outraged” by the Cambridge Analytica revelations — now snowballing into a massive privacy scandal.
In a statement reflecting on developments he writes: “Facebook has millions of times illegally distributed data of its users to various dodgy apps — without the consent of those affected. In 2011 we sent a legal complaint to the Irish Data Protection Commissioner on this. Facebook argued that this data transfer is perfectly legal and no changes were made. Now after the outrage surrounding Cambridge Analytica the Internet giant suddenly feels betrayed seven years later. Our records show: Facebook knew about this betrayal for years and previously argues that these practices are perfectly legal.”
So why did it take Facebook from September 2012 — when the DPC made its recommendations — until May 2014 and May 2015 to implement the changes and tighten app permissions?
The regulator’s spokesman told us it was “engaging” with Facebook over that period of time “to ensure that the change was made”. But he also said Facebook spent some time pushing back — questioning why changes to app permissions were necessary and dragging its feet on shuttering the friends’ data API.
“I think the reality is Facebook had questions as to whether they felt there was a need for them to make the changes that we were recommending,” said the spokesman. “And that was, I suppose, the level of engagement that we had with them. Because we were relatively strong that we felt yes we made the recommendation because we felt the change needed to be made. And that was the nature of the discussion. And as I say ultimately, ultimately the reality is that the change has been made. And it’s been made to an extent that such an issue couldn’t occur today.”
“That is a matter for Facebook themselves to answer as to why they took that period of time,” he added.
Of course we asked Facebook why it pushed back against the DPC’s recommendation in September 2012 — and whether it regrets not acting more swiftly to implement the changes to its APIs, given the crisis its business is now faced having breached user trust by failing to safeguard people’s data.
We also asked why Facebook users should trust Zuckerberg’s claim, also made in the CNN interview, that it’s now ‘open to being regulated’ — when its historical playbook is packed with examples of the polar opposite behavior, including ongoing attempts to circumvent existing EU privacy rules.
A Facebook spokeswoman acknowledged receipt of our questions this week — but the company has not responded to any of them.
The Irish DPC chief, Helen Dixon, also went on CNN this week to give her response to the Facebook-Cambridge Analytica data misuse crisis — calling for assurances from Facebook that it will properly police its own data protection policies in future.
“Even where Facebook have terms and policies in place for app developers, it doesn’t necessarily give us the assurance that those app developers are abiding by the policies Facebook have set, and that Facebook is active in terms of overseeing that there’s no leakage of personal data. And that conditions, such as the prohibition on selling on data to further third parties is being adhered to by app developers,” said Dixon.
“So I suppose what we want to see change and what we want to oversee with Facebook now and what we’re demanding answers from Facebook in relation to, is first of all what pre-clearance and what pre-authorization do they do before permitting app developers onto their platform. And secondly, once those app developers are operative and have apps collecting personal data what kind of follow up and active oversight steps does Facebook take to give us all reassurance that the type of issue that appears to have occurred in relation to Cambridge Analytica won’t happen again.”
Firefighting the raging privacy crisis, Zuckerberg has committed to conducting a historical audit of every app that had access to “a large amount” of user data around the time that Cambridge Analytica was able to harvest so much data.
So it remains to be seen what other data misuses Facebook will unearth — and have to confess to now, long after the fact.
But any other embarrassing data leaks will sit within the same unfortunate context — which is to say that Facebook could have prevented these problems if it had listened to the very valid concerns data protection experts were raising more than six years ago.
Instead, it chose to drag its feet. And the list of awkward questions for the Facebook CEO keeps getting longer.



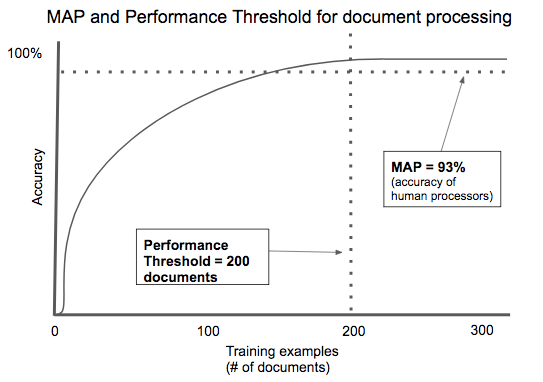 AI-powered contract processing is a good example of an application with a low performance threshold. There are thousands of contract types, but most of them share key fields: the parties involved, the items of value being exchanged, time frame, etc. Specific document types like mortgage applications or rental agreements are highly standardized in order to comply with regulation. Across multiple startups, we’ve seen algorithms that automatically process documents needing only a few hundred examples to train to an acceptable degree of accuracy.
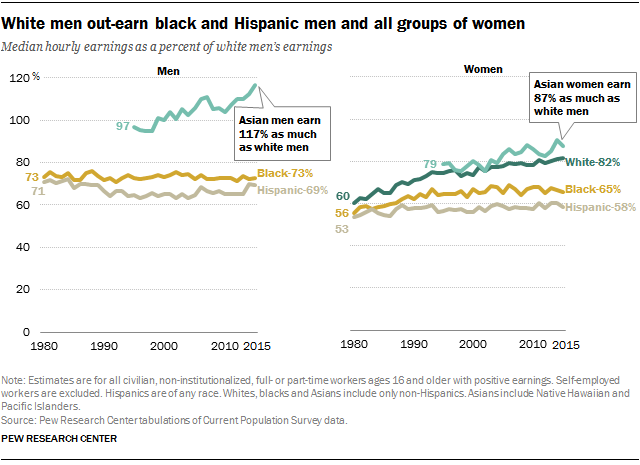
AI-powered contract processing is a good example of an application with a low performance threshold. There are thousands of contract types, but most of them share key fields: the parties involved, the items of value being exchanged, time frame, etc. Specific document types like mortgage applications or rental agreements are highly standardized in order to comply with regulation. Across multiple startups, we’ve seen algorithms that automatically process documents needing only a few hundred examples to train to an acceptable degree of accuracy.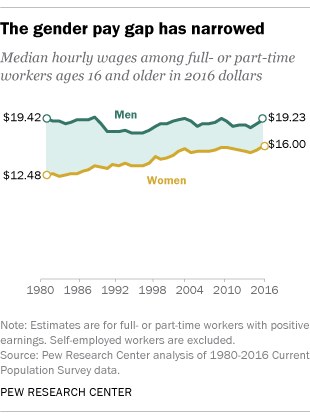 The racial pay gap also continues to exist. Similar to the gender pay gap, the racial pay gap has narrowed in recent years, but white men continue to out-earn black and Hispanic men, and all groups of women.
The racial pay gap also continues to exist. Similar to the gender pay gap, the racial pay gap has narrowed in recent years, but white men continue to out-earn black and Hispanic men, and all groups of women.